An Analysis of Day-to-Day Machine Translation Algorithms
Luiz Felipe Barbosa · 15 Apr 2022 · 18 min read
Introduction
The production of a quality translation (“the process of translating words or text from one language into another”1) has been for the most part confined to humans. The European Union, which consists of many countries that speak different languages, mainly utilizes teams of human translators when translating legislation or treaties as they demand the utmost precision and accuracy. However, if we just need to translate a web page or an email, most of us boot up an automatic translator to get a decent understanding of what is said. In an increasingly globalized world, communicating with people who use different languages has become essential. Hiring human translators, however, is time-consuming, expensive, and difficult to do in our day-to-day lives.
Machine translation solves this problem by providing a fast, clear, and mostly reliable alternative to human translation, even if coming at the cost of precision and accuracy. Our reliance on machine translation has grown significantly over the past decade2 and mistakes can have severe implications. Algorithms should be scrutinized, therefore, since proper training of the models is essential for the accuracy and precision of translation programs.
One of the core problems behind translation is that of ambiguity. Sentences may contain many different meanings. Take, for example, this sentence, “The girl kicked the bucket.” The sentence contains both a literal and an implicit meaning. Literally, the sentence may be describing the action of a girl kicking a bucket. Implicitly, however, the sentence may be claiming that the girl has died. If a program were to translate the sentence, it would most likely not account for the implicit meaning. A human translator, however, could form a sentence in the translated language that accounts for the implicit meaning.
This study aims to measure the efficiency of the various artificial intelligence models based on the accuracy and precision of the results obtained and identify which applications are most successful in mimicking human behavior.
What is Machine Translation?
Machine translation is a process by which programs translate text between languages. In its most basic form, machine translation performs substitutions between words in one language to words in another.
In 1933, Soviet scientist Peter Troyanskii invented the first systemized method to translate words from Russian to English. His proposal used a bilingual dictionary paired with grammatical roles between languages. However, his method only worked for specific cases where sentences did not contain ambiguity. After 20 years, Troyanskii’s forgotten method was found by two Soviet scientists sparking the beginning of the translation race.
In 1949, American researcher Warren Weaver at the Rockefeller Foundation laid a set of proposals towards tackling the translation problem based on information theory, code-breaking techniques used in World War II, and theories about the principles of natural language. On January 7, 1954 at IBM headquarters in New York, the first instance of machine translation took place. Forty-nine carefully selected sentences in Russian were translated to English. This marked the beginning of the Rule-Based Machine Translation era.

Figure 1 illustrates the process of Rule-Based Machine Translation, or RBMT. First, the text passes through a bilingual dictionary, then linguistic rules for the translation languages are applied to produce the final translation. Developments in computer hardware and software allowed for increasing bilingual dictionaries and hand-coded linguistic rules. However, RBMT was extremely hard to perfect as languages contain specific niches that are hard to account for. This is where machine learning enters the equation.
In 1950, Alan Turing introduced the question, “Can machines think?” This question inspired many researchers to develop programs that attempted to imitate the human mind, especially its ability to learn. In 1967, Frank Rosenblatt built the first computer with a machine learning algorithm based on trial and error. Machine learning provided a significant improvement to machine translation algorithms.
What is Machine Learning?
Machine learning is a branch of artificial intelligence where computers use data to simulate how humans learn. First, an algorithm identifies patterns in large data sets; historical trends are analyzed to produce a future model. Next, this model is evaluated against other data sets, further refining the accuracy and precision of the model. Finally, this process is repeated, optimizing the prediction of the model.
Supervised machine learning algorithms learn in three main parts: 1. The decision process: Data is input into the algorithm. The algorithm then returns a guess based on the previous patterns analyzed. 2. The error function: A function used to evaluate the prediction produced by the decision process. If known examples are available, the function makes a comparison assessing the accuracy of the model. 3. The updating/optimization process: If the prediction can better fit the points in the training set, the weights are adjusted, reducing the difference between the known examples and the prediction in the decision process. The algorithm will repeat this process until a target accuracy threshold is met.
When building a machine translation software, the algorithm’s decision process takes in the entire sentence, encoding and determining its meaning; then it converts the sentence to the new language based on a weighting system, to generate the most relevant words in the target language.
For the training process, the algorithm is fed multiple documents, articles, and idioms in many different languages, where weights are created for the association between these languages. It makes such associations as, are these words seen much together? Does the meaning of the sentence make sense? The error function comes in as a contributor to the translation project and the labeled elements of the dataset. If the translations are correct, the weights remain the same; if the translations are wrong, the weights are altered so the algorithm will not make the same mistake.
The algorithm updates automatically, improving itself with each run by analyzing the data. The nature of algorithm learning makes it unique as it does not need human intervention, opening the possibility of uncovering hidden insights.
Statistical Machine Translation (SMT)
A major revolution in machine translation came in the 1990s when researchers at IBM built translation software that did not use dictionaries or linguistic rules. Instead, the software analyzed two texts in different languages in which it attempted to identify the patterns within using machine learning—marking the birth of Statistical Machine Translation or SMT. This method removed the need for linguists and produced results with greater accuracy and precision than previous methods. However, SMT is best used for basic translation, as it does not utilize context to conduct the translations, making them frequently incorrect. As a result, the translations are functional but only of decent quality. The more texts used, the better the quality of the translation.
Significant improvements continued in the area of machine learning. On May 11, 1997, IBM’s Deep Blue chess engine beat the World Chess Champion Garry Kasparov; for the first time, a machine defeated a human in chess. The defeat of Garry Kasparov was a significant advancement, as it used cutting-edge technology to achieve one of the first major successes in artificial intelligence history.
In 2006, Google Translate was launched, which used a version of Rule Based SMT that utilized word rearrangement, article fillers, and batch translation. Article fillers provide words that are grammatically necessary in some languages, but not in others. For instance, if you translate the German sentence, “Ich will keine Äpfel,” the English translation is, “I do not want apples,” even though the word “do” is not necessary in German. Batch translation occurs when multiple words are translated together. The technique Google created is known as Phase-Based Machine Translation (PBMT), which attempts to incorporate the meaning of the sentences into their translated counterparts.
Neural Machine Translation (NMT)
Neural Machine Translation (NMT) has been the most successful translation method so far. The basic principle behind neural machine translation is the use of an encoder and a decoder. For example, imagine I am describing my dog: big ears, big body, white fur, big tail, big paws. If the description was precise enough, an accurate drawing of the dog could be constructed, even if you never saw the dog.

Figure 2 displays the encoding/decoding process. However, instead of images, the process happens with text, where the text is encoded, and a neural network is used to decode the text into another language. NMT systems have developed their own interlingual language.
Since NMT depends on isolating features of a text to encode, how are these features found? Deep learning is the solution. The main distinction between deep learning and the neural networks used for SMT is that deep learning finds the features without knowing their nature. If the deep learning neural network is large enough and there is the data, these features can be easily found. The fundamental advantage of NMT is that there is no need to apply techniques such as word rearrangement, article fillers, or batch translation.
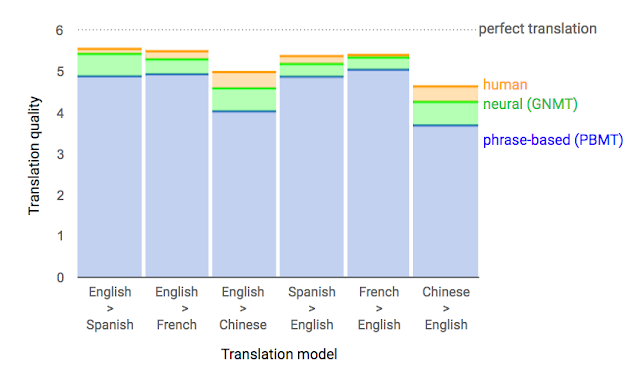
As seen in the table above provided by Google, GNMT (Google Neural Machine Translation) is significantly more precise and accurate when translating than the old PBMT approach, which would be a type of SMT. Still, the NMT translation quality is not as good compared to professional human translation.3
Experiment
I have chosen Google Translate, the most widely used translation software on the planet, and DeepL Translator, a program developed by a German company regarded as a solid competitor to Google Translate. Both softwares utilize neural machine translation and are widely used by many companies and individuals.
Google Translate offers 109 languages, while DeepL offers 26. Google Translate was initially trained on the European Parliament corpus database, which consists of documents translated by humans into the 23 European Union languages. On the other hand, DeepL was initially trained on the Linguee database, consisting of manually translated sentences and idioms from many different languages around the world.
I will be analyzing Google Translate and DeepL Translator by examining the data lost through multiple translations between different languages. For the experiment, I selected three texts in English, which I have classified as Beginner, Medium, and High-level depending on their complexity. Moreover, I have organized the languages on the DeepL Translator software by global usage. I then divided them into two groups consisting of 10 languages: Group 1 (Most Spoken): Chinese, French, Spanish, Russian, Portuguese, Japanese, German, Italian, Greek, and Hungarian. Group 2 (Least Spoken): Bulgarian, Czech, Danish, Dutch, Estonian, Finnish, Latvian, Lithuanian, Polish, and Romanian.
For the experiment, I will utilize Python to automate the translation process, conducting various translations within languages in the group. Firstly, I will translate the Easy, Medium, and High-level texts through Group 1, totaling ten translations, starting with the text in English and ending in Hungarian. I will then translate the product of the ten translations to English, noting down the results of the 11 translations. The process is then repeated with languages in Group 2.

The process described above will be repeated to test the effects of translating through the languages multiple times, but instead of looping through the list once, the code will loop ten times through the language groups.
Data on the number of characters and the number of proper nouns will be collected. To test for the change in information between translations, I decided to use the number of characters. Characters represent the amount of information in the text—the more characters, the more information, and the fewer characters, the fewer the information. Furthermore, proper nouns in the chosen texts portray the central focus of the text; if they are changed, the text completely shifts as the characters might not be the same (name change), they might be in a different location or they might be in a completely different time (change in month).
Hypothesis
Text 1 (Billy): “Billy always listens to his mother. He always does what she says. If his mother says, ‘Brush your teeth,’ Billy brushes his teeth. If his mother says, ‘Go to bed,’ Billy goes to bed. Billy is a very good boy. A good boy listens to his mother. His mother doesn’t have to ask him again. She asks him to do something one time, and she doesn’t ask again. Billy is a good boy. He does what his mother asks the first time. She doesn’t have to ask again. She tells Billy, ‘You are my best child.’ Of course Billy is her best child. Billy is her only child.”4
Text 1 was selected as the Easy text. It consists of simple sentences which are extremely easy to comprehend and will be most likely to lead to precise and accurate translations. Furthermore, Text 1 repeats the proper noun “Billy,” which should mostly remain unchanged throughout the translations. The lack of adjectives should facilitate the translation process, making the meaning of the sentences clear and, therefore, making it more likely that the text will remain the same after multiple translations, leading to few character losses.
Text 2 (Grace): “Miss Grace Spivey arrived in Threestep, Georgia, in August 1938. She stepped off the train wearing a pair of thick-soled boots suitable for hiking, a navy blue dress, and a little white tam that rode the waves of her red hair at a gravity-defying angle. August was a hellish month to step off the train in Georgia, although it was nothing, she said, compared to the 119 degrees that greeted her when she arrived one time in Timbuktu, which, she assured us, was a real place in Africa. I believe her remark irritated some of the people gathered to welcome her on the burned grass alongside the tracks. When folks are sweating through their shorts, they don’t like to hear that this is nothing compared to someplace else. Irritated or not, the majority of those present were inclined to see the arrival of the new schoolteacher in a positive light. Hard times were still upon us in 1938, but, like my momma said, ‘We weren’t no poorer than we’d ever been,’ and the citizens of Threestep were in the mood for a little excitement.”5
Text 2 was selected as the Medium text. It consists of descriptive sentences, which add a level of complexity to the comprehension of the text and make the sentences’ meaning significantly harder to identify. However, Text 2 contains many common proper nouns such as “Grace,” “Spivey,” “August,” “Threestep,” and “Georgia,” which will remain throughout the translations. The most descriptive text will make the translation process harder as the sentence’s meaning will be more complicated for the program to grasp, leading to high character losses.
Text 3 (Sydney): “‘You were very sound, Sydney, in the matter of those crown witnesses today. Every question told.’ ‘I always am sound; am I not?’ ‘I don’t gainsay it. What has roughened your temper? Put some punch to it and smooth it again.’ With a deprecatory grunt, Carton complied. ‘The old Sydney Carton of old Shrewsbury School,’ said Stryver, nodding his head over him as he reviewed him in the present and the past, ‘the old seesaw Sydney. Up one minute and down the next; now in spirits and now in despondency!’ ‘Ah!’ returned the other, sighing: ‘Yes! The same Sydney, with the same luck. Even then, I did exercises for other boys, and seldom did my own.’”6
Text 3 was selected as the High-level text. It consists of two characters speaking, adding an extra layer of complexity to the text. They utilize words such as “sound,” which in the text means “sense” and not “noise,” making the meaning of the sentence harder to identify. Much like the other two texts, the proper nouns, such as “Sydney,” “Stryver,” and “Shrewsbury,” will most likely be maintained throughout the translation process. The text contains many metaphors, which I believe the translation process will not preserve as they consist of words with multiple meanings, and context may not be transferred through the translations, leading to greater character loss.
Results: 10 Translations
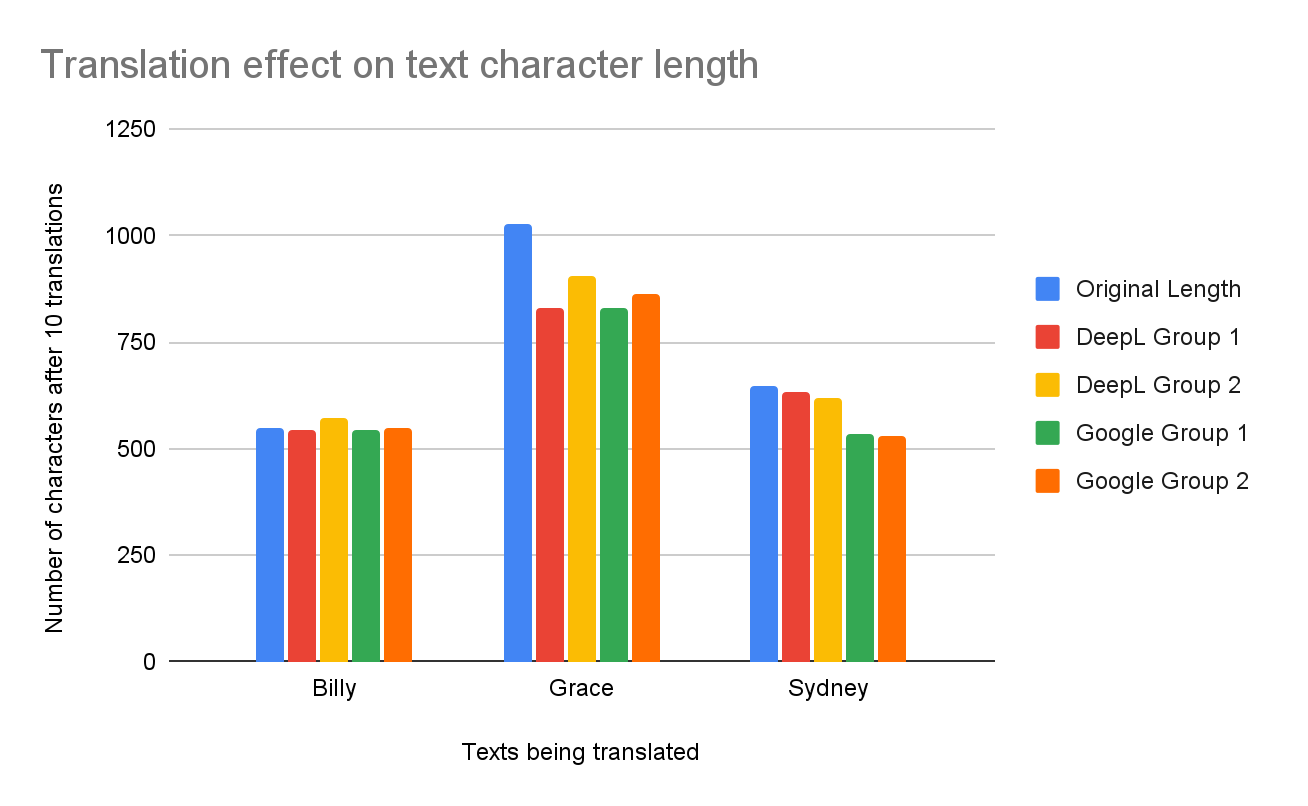
Figure 5 displays the number of characters before and after the text is translated ten times. As we can see, as a result of the translations, most texts decreased in size, except the unexpected result of Billy DeepL Group 2, where the text increased from 550 → 571. Grace Google Group 1 was the translation that lost the most characters compared to the original, going from 1027 → 828, a 19.4% drop. However, Grace DeepL Group 1 dropped 19% from 1027 → 832, almost receiving the title of the most significant drop from the original. On the other hand, Billy Google Group 2 had the slightest character change from 550 → 547, a 0.005% drop.
As shown in Figure 6, the DeepL translation software consistently outperformed Google Translate; DeepL had an average character loss of 5.8%, while Google Translate had an average character loss of 12.2%. Google Group 1 had the largest average character loss totaling 12.6%; DeepL Group 2 had the smallest change with an average loss of 4.2%. Against the hypothesis, the Billy text, the easiest, had the smallest average loss per text; in fact, it grew as represented by the negative number. Again, against the hypothesis, the Grace text had the largest character loss averaging 16.6%, showing it was the hardest text for the translation software to translate. The Sydney text proved quite challenging for Google Translate, where Group 1 had a 17.4% character loss and Group 2 had an 18.5% loss. In contrast, DeepL had ease in maintaining the character length of the text, with Group 1 at a 2.3% loss and Group 2 at a 4.6% loss. DeepL Group 2 had the most success, with the translations having an average character loss of 4.6% throughout all texts.
| Texts | DeepL Group 1 | DeepL Group 2 | Google Group 1 | Google Group 2 | Avg loss per text |
|---|---|---|---|---|---|
| Billy | 1.1% | −3.8% | 1.1% | 0.5% | −0.3% |
| Grace | 19.0% | 12.0% | 19.4% | 16.2% | 16.6% |
| Sydney | 2.3% | 4.6% | 17.4% | 18.5% | 10.7% |
| Avg loss per group | 7.5% | 4.3% | 12.6% | 11.7% | |
| DeepL avg loss | 5.9% | Google avg loss | 12.2% |
Results: 100 Translations
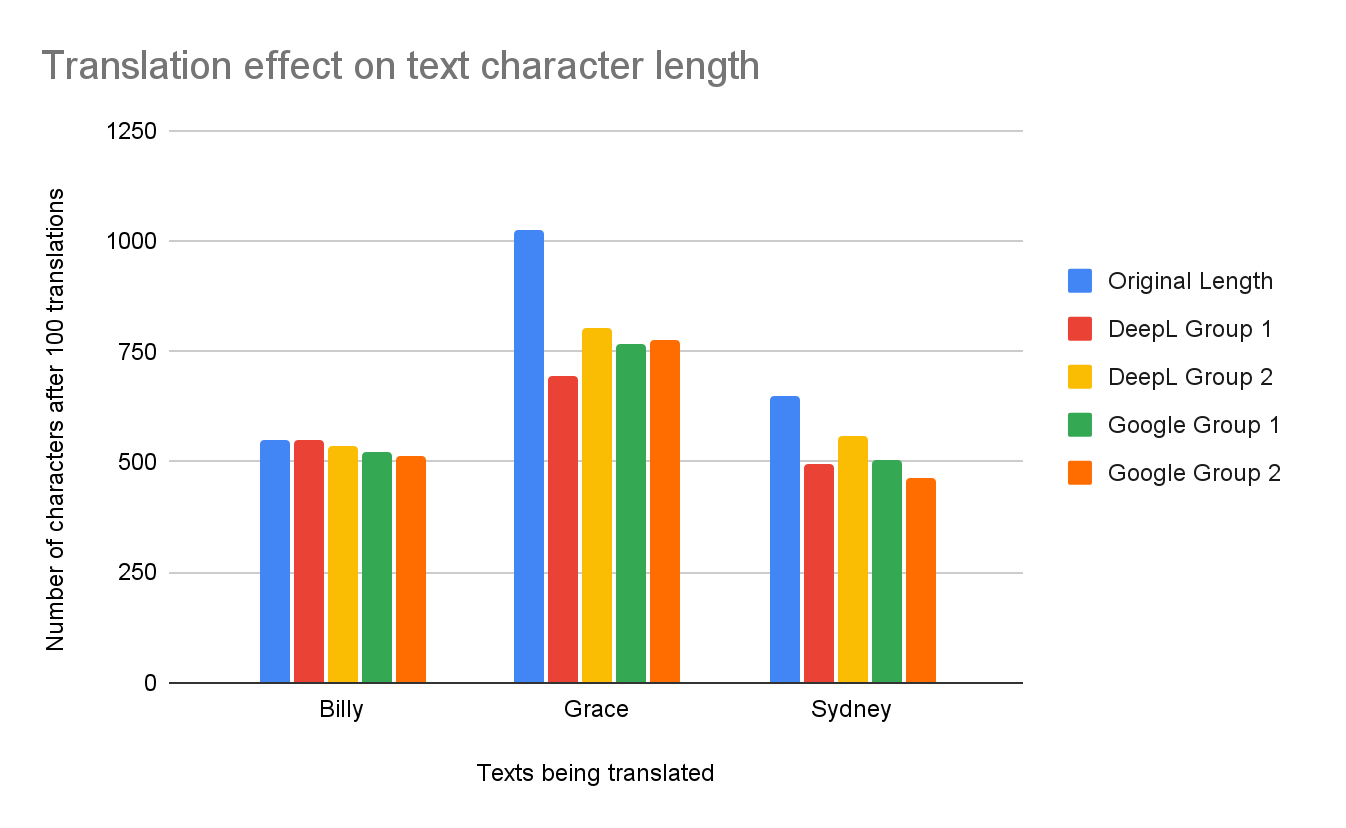
Figure 7 displays the number of characters before and after the text is translated 100 times. Much like with 10 translations, 100 translations led to significant decreases in the size of the texts. DeepL once more produced an unexpected result: Billy DeepL Group 1 increased from 550 → 551 compared to the original. Unlike with 10 translations, Grace DeepL Group 1 was the translation with most characters lost compared to the original, going from 1027 → 694, a 32.4% drop. Billy DeepL Group 2 had the smallest decrease in characters, from 550 → 537, a 2.3% drop.
Figure 8 displays that DeepL Translator outperformed Google Translate; DeepL had an average character loss of 15.6%, while Google Translate had an average character loss of 18.6%. Google Group 2 had the largest average character loss, totaling 19.7%, whereas DeepL Group 2 had the smallest change with an average loss of 12.6%. Following the hypothesis, the average loss of the Billy text came in at 3.5%, showing that it was the easiest text to translate. On the other hand, the Grace text persisted as the hardest text to translate, coming in at 25.9% character loss. The Sydney text’s average character loss doubled from the 10 to 100 translations, going from 10.7% loss to 21.9%. Unlike with the 10 translations, the Sydney text had a harder time maintaining the character amount for the 100 translations, increasing from 3.5% to 18.6%. Nevertheless, the general trends continue, with DeepL Group 2 having the lowest character loss and the Grace text being the hardest to translate.
| Texts | DeepL Group 1 | DeepL Group 2 | Google Group 1 | Google Group 2 | Avg loss per text |
|---|---|---|---|---|---|
| Billy | −0.2% | 2.4% | 5.3% | 6.5% | 3.5% |
| Grace | 32.4% | 21.8% | 25.1% | 24.3% | 25.9% |
| Sydney | 23.6% | 13.6% | 22.2% | 28.2% | 21.9% |
| Avg loss per group | 18.6% | 12.6% | 17.5% | 19.7% | |
| DeepL avg loss | 15.6% | Google avg loss | 18.6% |
Results: Proper Nouns
Figure 9 displays the change in the number of proper nouns before and after the 10 translations. The number of times the word “Billy” appeared in the original Billy text was 8; the word “Grace” was 1, “Spivey” was 1, and “Threestep” was 2 in the original Grace text; and so on. In the Billy text in Google Group 2, Google Translate replaced the two missing instances of the word “Billy” with “Bill.” The results show that the words that were the most difficult to be preserved were “Threestep” and “Stryver;” in the original Grace text, “Threestep” appears twice, however in the translations, it got changed to words like “Tresloop,” “Sabu” and “Trestle.” This might be because the algorithms utilize an autocorrect to check for spelling mistakes, altering the name of the town. The name “Stryver” was only preserved in the DeepL Group 1 translation; in the other three translations, it was changed to “Stravers,” “Striver,” and “Stranger.” Furthermore, the proper nouns “Grace,” “August,” and “Georgia” were all maintained throughout the translations as they are commonly found and used words. Unexpectedly, the word “Georgia” appeared three times in Google Group 2. The word “Sydney” weirdly was not preserved throughout the DeepL translations; it was altered to words like “Sidney” and sometimes removed entirely from the texts.
| Texts | Original | DeepL Group 1 | DeepL Group 2 | Google Group 1 | Google Group 2 |
|---|---|---|---|---|---|
| Billy | 8 | 7 | 8 | 8 | 6 |
| Grace | 1, 1, 2, 2, 2 | 1, 1, 0, 2, 2 | 1, 1, 0, 2, 2 | 1, 1, 0, 2, 2 | 1, 0, 0, 2, 3 |
| Sydney | 4, 1, 1 | 1, 1, 1 | 1, 0, 1 | 4, 0, 1 | 4, 0, 1 |
Figure 10 displays the change in the number of proper nouns before and after the 100 translations. In the Billy text in Google Group 2, Google Translate replaced the three missing instances of the word “Billy” with “Bill.” The results further show that the words that were the most difficult to be preserved were “Threestep” and “Stryver;” in the original Grace text, “Threestep” appears twice, however in the translations, it got changed to things like “Trezope,” “Tristepe,” “Mr and Mrs Trevor” and “Trade.” This might be because the algorithms have no way to translate a word that has no translation, as it is a made-up town. The name “Stryver” again was only preserved in the DeepL Group 1 translation; in the other three translations, it was changed to “Stravers,” “Stratford,” and “Streamer.” Furthermore, the proper nouns “Grace,” “August,” and “Georgia” were all maintained throughout the translations as they are commonly found and used words. Unexpectedly, the word “Georgia” appeared three times in Google Group 2. Again, the word “Sydney” weirdly was not preserved throughout the DeepL translations, as it was altered to words like “Sidney” and sometimes removed.
| Texts | Original | DeepL Group 1 | DeepL Group 2 | Google Group 1 | Google Group 2 |
|---|---|---|---|---|---|
| Billy | 8 | 7 | 8 | 8 | 5 |
| Grace | 1, 1, 2, 2, 2 | 1, 1, 0, 2, 2 | 1, 1, 0, 2, 2 | 1, 1, 0, 2, 2 | 1, 0, 0, 2, 3 |
| Sydney | 4, 1, 1 | 0, 1, 1 | 1, 0, 1 | 4, 0, 1 | 4, 0, 1 |
Conclusion
The Billy text, as predicted, proved to be the easiest one to translate; it had the lowest average character loss levels out of the texts and had the highest proper noun similarity. Furthermore, the simplicity of the text facilitated the translation process as the words in the text are widely used. Nevertheless, it still proved challenging to translate as some languages do not have direct definitions for English words.
Surprisingly, the Grace text, classified as Medium level, was the hardest one to translate; it had the highest character loss and lowest proper noun similarity. Its highly descriptive nature proved difficult for the translation algorithms as the descriptions may obfuscate the meaning of the sentences, often leading to significant cuts in the number of characters. In addition, when faced with never seen before words like “Threestep,” the attempted interpretation leads to a compounding inaccuracy in each step, making the word less intelligible from the original.
The Sydney text was not the hardest by the criteria established in the experiment, but when attempting to understand the raw data, the Sydney text was the one with the least resemblance to its original version. However, the DeepL translation maintained the structure and character number of the text, making it way better than Google Translate. Like in the Grace text, the Sydney text had words like “Stryver,” the man’s name, which faced the same fate as “Threestep,” endlessly compounding, forming random words with some resemblance to the original.
In conclusion, machine translation algorithms are efficient in maintaining accuracy and precision throughout the process. However, they still fall behind in identifying ambiguity within the sentences, often cutting and simplifying the texts tested. The DeepL Translator software outperformed Google Translate in both character loss and the proper nouns change categories, proving itself the most efficient translation engine of the two.
Evaluation
The experiment was a success. However, a couple of improvements can be made. Firstly, I could only perform 30 translations before having my connection timed out for a couple of hours by Google’s servers, inhibiting the creation of a trend showing how an increasing number of translations impacts the result. Secondly, if the genre, structures, or lengths of the texts were varied, the results could have been entirely different. Furthermore, the languages chosen do not paint a clear picture of Google Translate as it offers over 109 languages, and the 20 languages chosen are of DeepL’s specialty; most likely if the languages were in different orders or groups, a different result would’ve been achieved. Also, the context and meaning of the sentences were not accounted for as I could not find a good measure for such. Finally, the analysis of only two software programs limits the possibility of finding the most efficient ones as they are not good representations of a whole since other software utilize different databases and different forms of NMT.
Further research on the subject may include analyzing the meaning and comparing it to the original text. The analysis of the meaning will produce results with greater accuracy and precision as it will be tackling the central problem the translation engines face, which is sentence ambiguity. Moreover, analyzing a greater variety of texts will help identify the variables that make the texts’ translations problematic. In addition, analyzing the punctuation of the texts may provide a clearer insight into the precision and accuracy of the translation. Finally, conducting more than 100 translations and analyzing different software may give greater insight in answering the question of What are the differences in efficiency in the day-to-day use of machine learning translation algorithms?
Works Cited
- 2Uadmin. “What Is Machine Learning? - I School Online.” UCB-UMT, Berkeley, 29 Jan. 2021, ischoolonline.berkeley.edu/blog/what-is-machine-learning.
- Education, IBM Cloud. “Artificial Intelligence (AI).” IBM, 16 Sept. 2021, www.ibm.com/cloud/learn/what-is-artificial-intelligence.
- ———. “Machine Learning.” IBM, 5 Nov. 2021, www.ibm.com/cloud/learn/machine-learning.
- freeCodeCamp.org. “A History of Machine Translation from the Cold War to Deep Learning.” FreeCodeCamp.Org, 1 Mar. 2018, www.freecodecamp.org/news/a-history-of-machine-translation-from-the-cold-war-to-deep-learning-f1d335ce8b5.
- “A Good Boy.” English Learning, www.eslfast.com/supereasy/se/supereasy001.htm. Accessed 12 Dec. 2021.
- Google Inc. “Translated EU Documents Used by Google to Develop Its Language Software.” European Parliament, 14 May 2010, www.europarl.europa.eu/doceo/document/E-7-2010-3436_EN.html?redirect.
- “A Neural Network for Machine Translation, at Production Scale.” Google AI Blog, 27 Sept. 2016, ai.googleblog.com/2016/09/a-neural-network-for-machine.html.
- Norvig, Peter, and Stuart Russell. Artificial Intelligence: A Modern Approach, Global Edition. 4th ed., Pearson, 2021.
- Post, Nicole. “Different Types Of Machine Translation.” Localize Blog, 26 Oct. 2021, localizejs.com/articles/types-of-machine-translation.
- “Recent Advances in Google Translate.” Google AI Blog, 8 Jun. 2020, ai.googleblog.com/2020/06/recent-advances-in-google-translate.html.
- Team, Revolutionized. “Here Is How DeepL Translator and Google Translate Compare.” Revolutionized, 28 Oct. 2021, revolutionized.com/deepl-translator-vs-google-translate.
- Wu, Yonghui. “Google’s Neural Machine Translation System: Bridging the Gap.” ArXiv.Org, Cornell University, 26 Sept. 2016, arxiv.org/abs/1609.08144.
- “SAT.” Golden Key Education, goldenkeytutor.com/en/free-quiz/sat/.
- Dickens, Charles. “A Tale of Two Cities (Chap 2.5).” Genius, genius.com/Charles-dickens-a-tale-of-two-cities-chap-25-annotated.
- “Zero-Shot Translation with Google’s Multilingual Neural Machine Translation System.” Google AI Blog, 22 Nov. 2016, ai.googleblog.com/2016/11/zero-shot-translation-with-googles.html.
More Articles
An Analysis of PressTV and Three Privately-Owned Israeli News Channels on Telegram
12 May 2026A comparative NLP analysis of PressTV and three privately owned Israeli Telegram news channels, showing how ownership shapes cadence, topic structure, and media strategy while all four converge around a fear-dominant Iran-Israel-US frame.
Calibration Errors and Trading Opportunities in Kalshi Political Speech Mention Markets
27 Mar 2026A study of 7,320 Kalshi political speech mention contracts showing that these markets learn over time but still overprice low-probability YES outcomes, leaving the NO side materially stronger after fees.
Cross-Category Calibration Analysis of Kalshi Mention Markets
15 Mar 2026A cross-category study of 18,948 Kalshi mention contracts showing that calibration improves as events approach, but longshot bias still leaves the NO side systematically underpriced.